
Uncertainty quantification (UQ) for large language models (LLMs) is a key building block for safety guardrails of daily LLM applications. Yet, even as LLM agents are increasingly deployed in highly complex tasks, most UQ research still centers on single-turn question-answering. We argue that UQ research must shift to realistic settings with interactive agents, and that a new principled framework for agent UQ is needed. This position paper presents three pillars to build a solid ground for future agent UQ research: (1. Foundations) We present the first general formulation of agent UQ that subsumes broad classes of existing UQ setups; (2. Challenges) We identify four technical challenges specifically tied to agentic setups---selection of uncertainty estimator, uncertainty of heterogeneous entities, modeling uncertainty dynamics in interactive systems, and lack of fine-grained benchmarks---with numerical analysis on a real-world agent benchmark, \(\tau^2\)-bench; (3. Future Directions) We conclude with noting on the practical implications of agent UQ and remaining open problems as forward-looking discussion for future explorations.
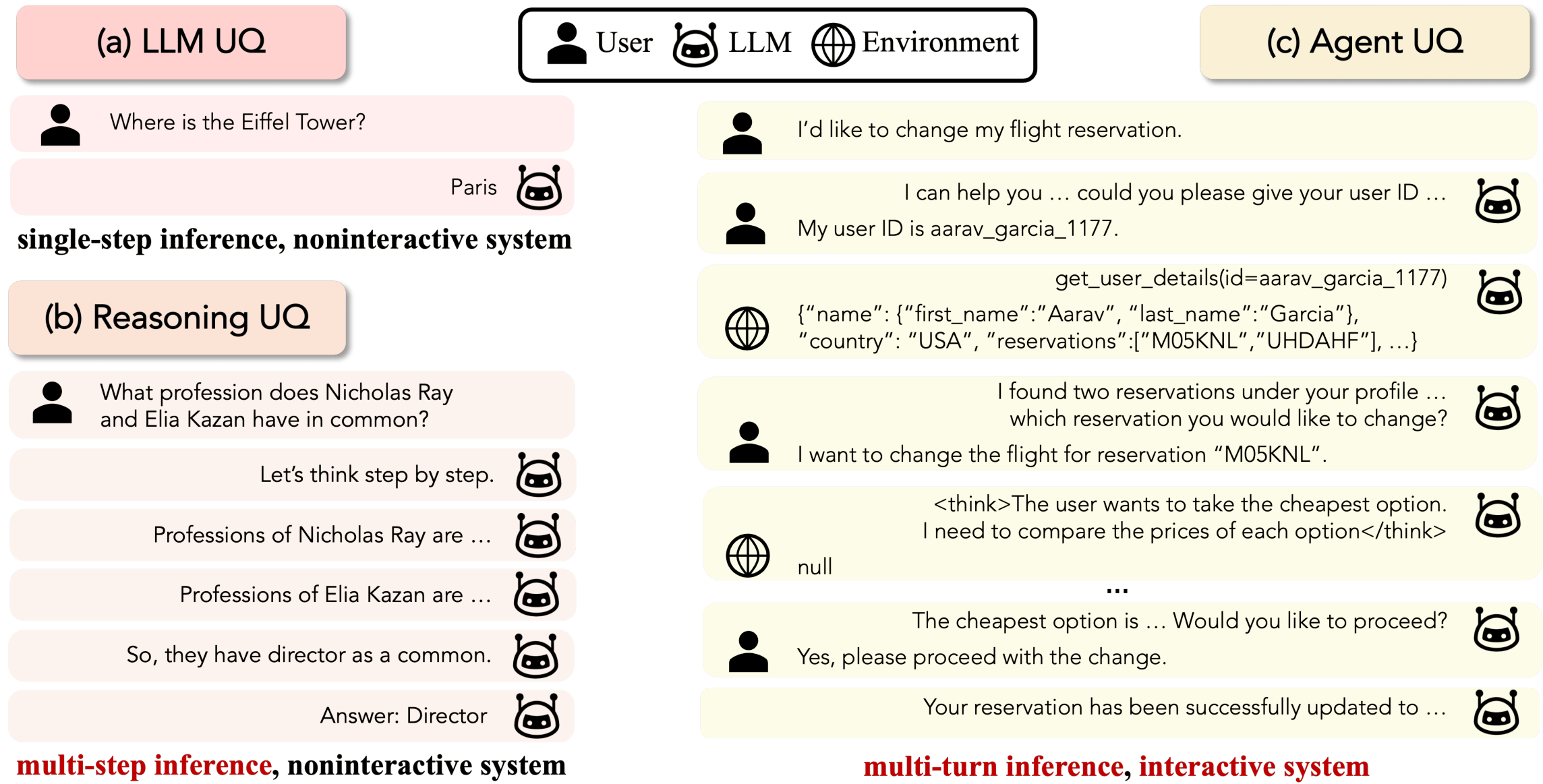
LLM agents now take consequential real-world actions like making bookings and modifying databases, where failures go beyond incorrect text generations to include costly or irreversible outcomes. Most existing UQ research treats LLMs as single-turn, static inference systems, which doesn't account for the multi-turn, interactive nature of agentic settings where new information is continuously acquired through interactions. We argue that UQ research must shift toward these realistic agent scenarios.
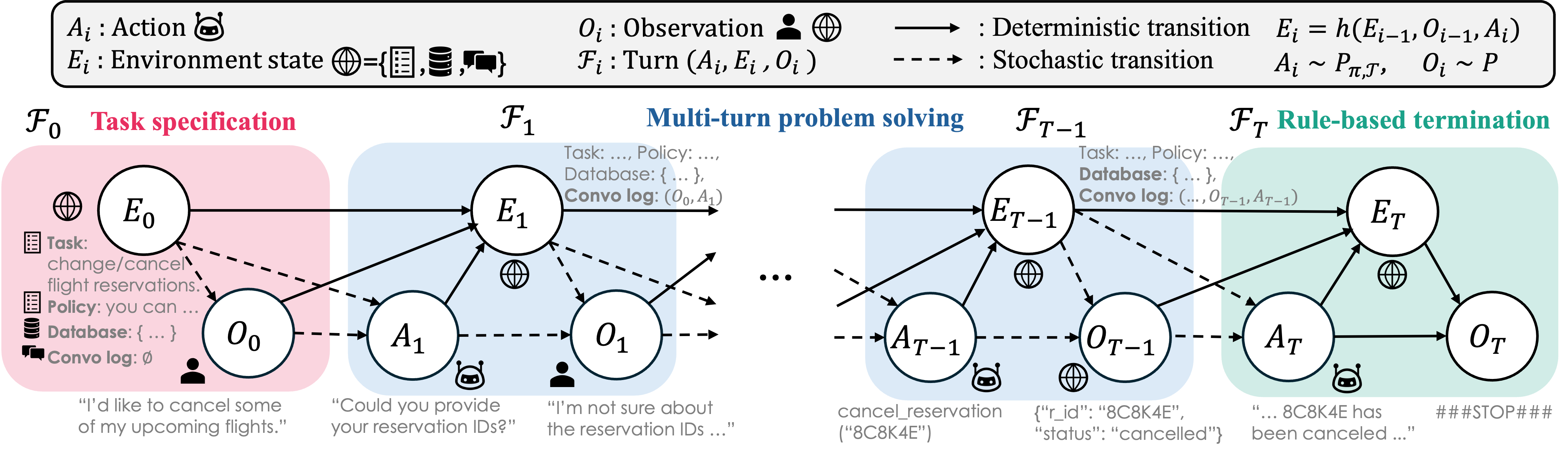
We define a stochastic agent as a sequence of actions, observations, and environment states forming a trajectory. Using a dynamic Bayesian network, the joint probability of a trajectory is factorized into per-turn components, enabling total uncertainty to be decomposed as a sum of action and observation uncertainties at each step via the chain rule under some uncertainty instances. This formulation subsumes existing single-step LLM UQ and multi-step reasoning UQ setups as special cases, providing a unified theoretical lens for various UQ setups under one coherent formulation grounded in probabilistic sequential modeling.

Three representative UQ methods, output probability-based, consistency-based, and verbalized confidence methods reveal clear trade-offs along three dimensions: accessibility, inference-time cost overhead, and theoretical grounding; Agentic scaffold turns these weaknesses into much more serious challenges: (1) probability-based methods cannot be applied to most frontier LLMs that centered at challenging agent benchmarks, as they do not consistently provide probability outputs; moreover, free-form long generation makes aggregated token probabilities less informative; (2) consistency-based methods become infeasible due to their prohibitively high inference cost in long-horizon, multi-turn settings; and (3) dynamically expanding context memory of agent, often coupled with noisy observations, results in increasingly inflated and unreliable verbalized confidence.
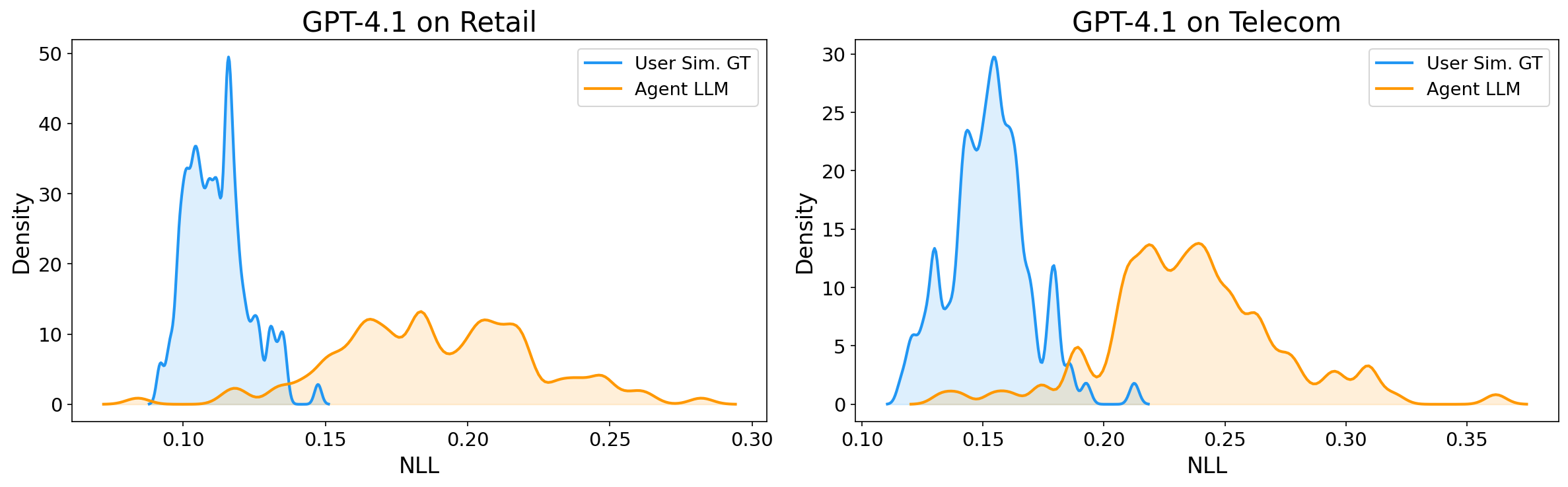
Inference of agents involves not only the actions from the agent itself, but more importantly, observations through the conversations with the user and interactions with the environment via tools. There are no trivial means to estimate the uncertainty of observations that come from these heterogeneous external entities without additional assumptions on the nature of the entities, departing from the epistemic uncertainty of the agent-self.
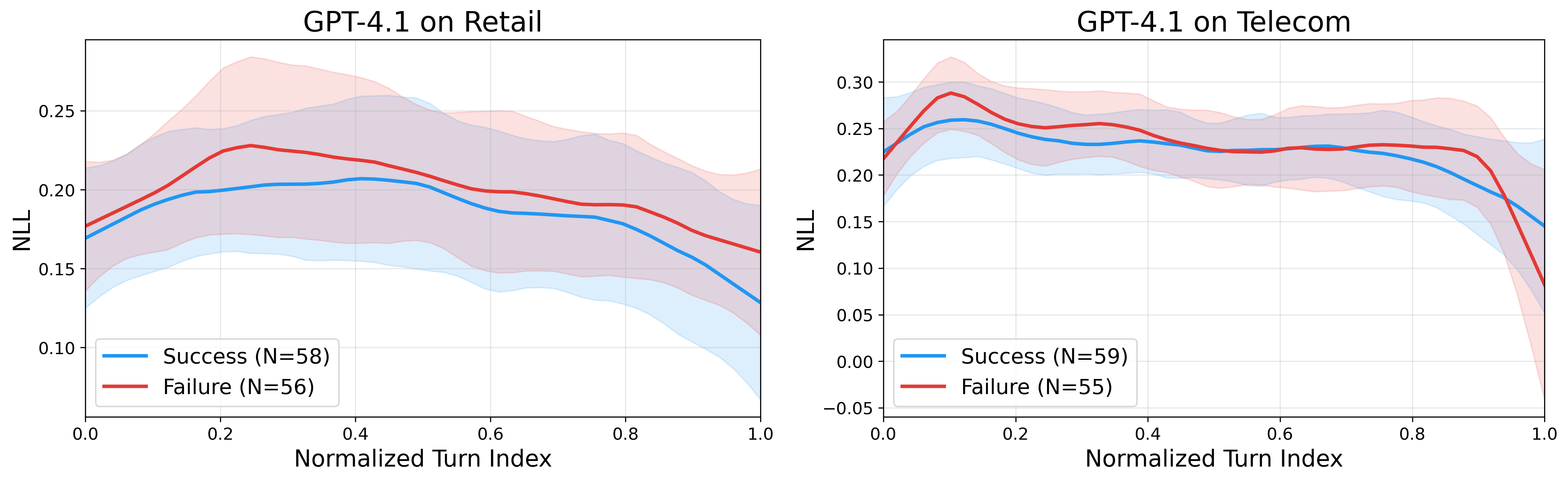
An agent in the open environment can gather extra information, make clarifications, and request confirmations at each step by interacting with the user and databases through conversations and tool-calling. These interactive actions are the driving force of goal achievement in the complex (and usually under-specified) agentic tasks in the wild. Therefore, agent UQ should reflect conditional uncertainty reduction through information-seeking behavior as well as the uncertainty propagation. Unfortunately, most existing multi-step UQ approaches just naively aggregate uncertainty over turns, while neglecting the interactivity of actions and conditional reducibility of uncertainty.
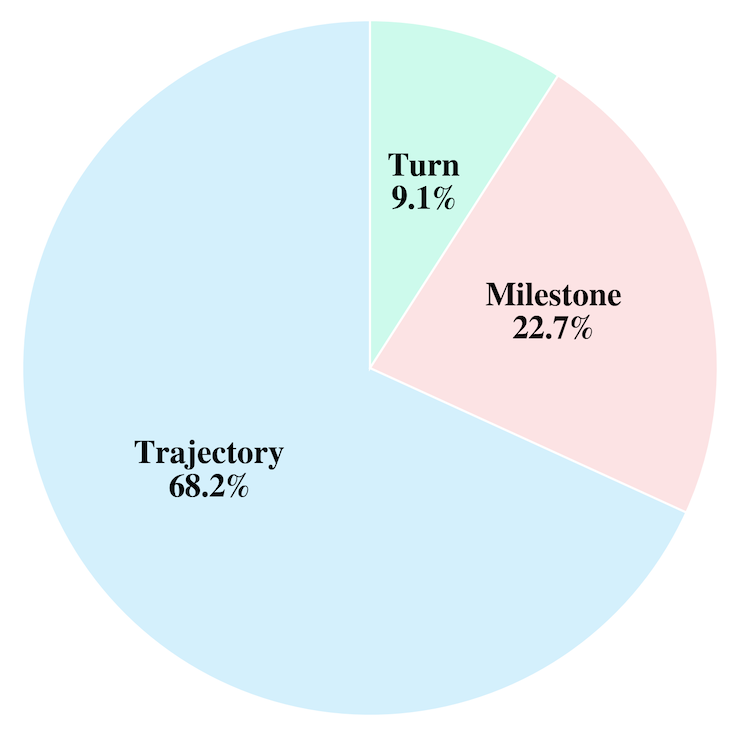
Annotating long-horizon agent trajectories incurs non-trivial effort and cost. The absence of fine-grained benchmarks becomes a natural bottleneck to developing a solid UQ method for agents. We provide a mini-survey of existing LLM agent benchmarks, where we categorize 44 benchmarks into three classes depending on evaluation granularity: trajectory-level (conducted once at the end of the trajectory), milestone-level (involving several intermediate milestones or events), and turn-level (conducted at every single turn). Results show that fine-grained evaluation protocols are very scarce.
Developing the agent UQ framework is not merely a theoretical exercise but a prerequisite for deploying LLM agents in non-deterministic real environments. We outline implications for frontier LLM research and three specialized domains: healthcare, software engineering, and cyber-physical systems, in which agent UQ may have profound downstream effects, thereby incentivizing policymakers, practitioners, and researchers.
Not only for the technical challenges we can specify immediately, but there is also a bundle of open problems that we need to address for the future of agent UQ: How can we distinguish the source of uncertainty under intrinsic solution multiplcity?; Is it enough to consider the task failure as solely target for uncertainty evaluation?; How should we define and handle the uncertainty dynamics in multi-agent or self-evolving agent systems?
We sincerely thank Artem Shelmanov, Shawn Im, Hyeong Kyu Choi, Jongwon Jeong, Eunsu Kim, Mingyu Kim, Ayoung Lee, JungEun Kim, Hayun Lee, Hoyoon Byun, and Kyungwoo Song for their sharp feedback on the initial draft. This work is supported in part by the AFOSR Young Investigator Program under award number FA9550-23-1-0184, National Science Foundation under awards IIS-2237037 and IIS-2331669, Office of Naval Research under grant number N00014-23-1-2643, Schmidt Sciences Foundation, Open Philanthropy, Alfred P. Sloan Fellowship, and gifts from Google and Amazon. Paul Bogdan acknowledges the support by the National Science Foundation (NSF) under the NSF Award 2243104 under the Center for Complex Particle Systems (COMPASS), NSF Mid-Career Advancement Award BCS-2527046, U.S. Army Research Office (ARO) under Grant No. W911NF-23-1-0111, Defense Advanced Research Projects Agency (DARPA) Young Faculty Award and DARPA Director Fellowship Award, Okawa foundation award, National Institute of Health (NIH) under R01 AG 079957, and Intel faculty awards.
@article{oh2026uncertainty,
title={Uncertainty Quantification in LLM Agents: Foundations, Emerging Challenges, and Opportunities},
author={Oh, Changdae and Park, Seongheon and Kim, To Eun and Li, Jiatong and Li, Wendi and Yeh, Samuel and Du, Xuefeng and Hassani, Hamed and Bogdan, Paul and Song, Dawn and Li, Sharon},
journal={arXiv preprint arXiv:2602.05073},
year={2026}
}